
刚刚,Mistral AI最新磁力链放出!8x22B MoE模型,281GB解禁
刚刚,Mistral AI最新磁力链放出!8x22B MoE模型,281GB解禁一条磁力链,Mistral AI又来闷声不响搞事情。
来自主题: AI资讯
7148 点击 2024-04-11 16:39
一条磁力链,Mistral AI又来闷声不响搞事情。

Stability AI推出Stable LM 2 12B模型,作为其新模型系列的进一步升级,该模型基于七种语言的2万亿Token进行训练,拥有更多参数和更强性能,据称在某些基准下能超越Llama 2 70B。
Anthropic 发现一种新型越狱漏洞并给出了高效的缓解方案,可以将攻击成功率从 61% 降至 2%。

【新智元导读】就在刚刚,全球最强开源大模型王座易主,创业公司Databricks发布的DBRX,超越了Llama 2、Mixtral和Grok-1。MoE又立大功!这个过程只用了2个月,1000万美元,和3100块H100。

这是迄今为止最强大的开源大语言模型,超越了 Llama 2、Mistral 和马斯克刚刚开源的 Grok-1。

AI世界的进化快的有点跟不上了。刚刚,全球最强最大AI芯片WSE-3发布,4万亿晶体管5nm工艺制程。更厉害的是,WSE-3打造的单个超算可训出24万亿参数模型,相当于GPT-4/Gemini的十倍大。

LLM开源从Infra做起!Meta公布了自己训练Llama 3的H100集群细节,看来Llama 3快来了。
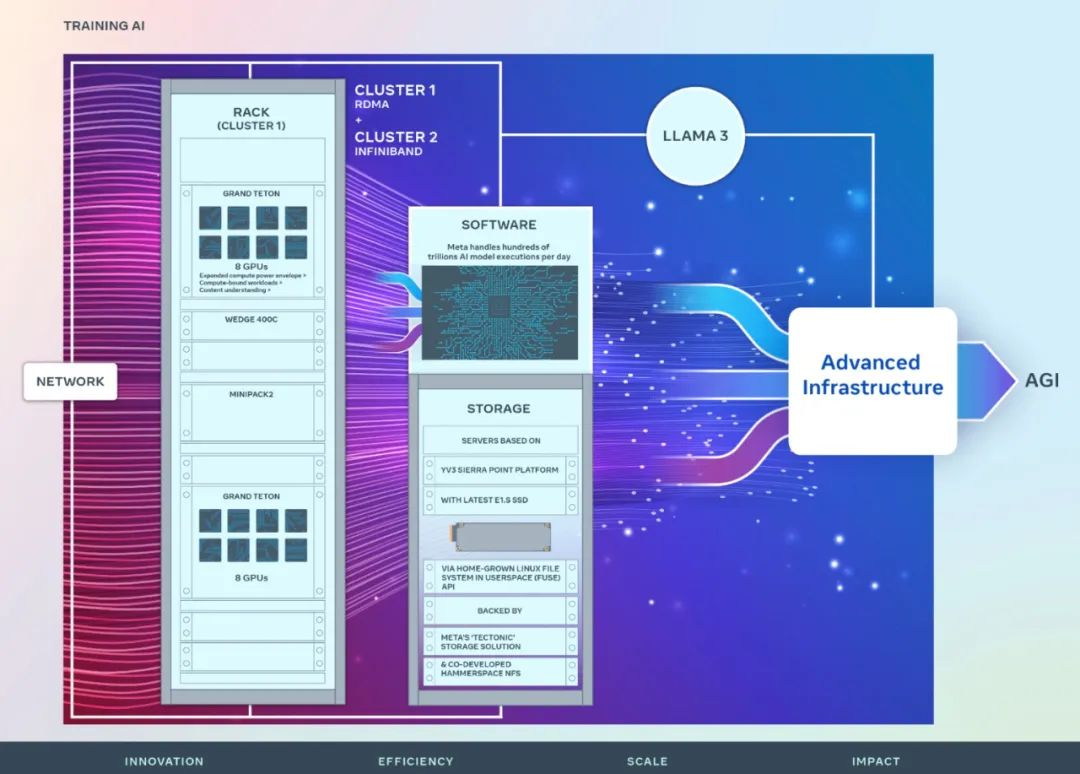
刚刚,Meta 宣布推出两个 24k GPU 集群(共 49152 个 H100),标志着 Meta 为人工智能的未来做出了一笔重大的投资。

半年多来,Meta 开源的 LLaMA 架构在 LLM 中经受了考验并大获成功(训练稳定、容易做 scaling)。

参照SuperCLUE(中文通用大模型综合性测评基准)框架专门定制了1000道题目集,一一测试了ChatGPT4、 智谱chatGLM-4、Baichuan2-Turbo、百度ERNIE-Bot 4.0、Yi-34B-chat、llama 2等模型在保险业务上的表现。